Databricks Workflows
Overview
You can integrate Sifflet with Databricks Workflows to monitor your data pipelines and ensure data quality at each step. By connecting Sifflet to your Databricks environment, you gain end-to-end visibility of your data, from ingestion to consumption.
This integration allows you to:
- Monitor the status of your Databricks Workflows jobs directly within Sifflet, providing a unified view of your data orchestration and quality.
- Trace data lineage from your Databricks jobs to your downstream dashboards and reports, enabling you to quickly identify the root cause of any data issue.
- Proactively stop bad data from propagating through your pipelines by leveraging Sifflet's data quality monitors within your Databricks Workflows jobs.
Prerequisites
Before you can configure the Databricks Workflows integration, you must first set up the standard Databricks integration in Sifflet. This involves creating a dedicated Service Principal with the necessary permissions to access your Databricks environment.
For detailed instructions on how to set up the Databricks integration, please refer to our Databricks integration documentation.
Setup
Once you have successfully configured the Databricks integration, you can proceed with setting up the Databricks Workflows integration.
-
Navigate to the Integrations page in Sifflet and click on New Source.
-
Select Databricks Workflows from the list of available integrations.
-
In the configuration form, provide the following information:
- Host: The full URL of your Databricks instance (e.g.,
https://<your-workspace>.cloud.databricks.com). - Port: The default value is 443; only change it if you're using a custom port.
- HTTP Path: The HTTP path of the Databricks SQL Warehouse that Sifflet will use to run queries.
- Credential: The Sifflet credential that you created when setting up the standard Databricks integration.
- Host: The full URL of your Databricks instance (e.g.,
-
Click on Test Connection to confirm that everything is configured correctly
-
Click on Save to create the integration.
Once the integration is created, Sifflet will start ingesting metadata from your Databricks Workflows, and you will be able to see your jobs and their status in the Sifflet catalog and lineage views.
Using the Integration
Catalog & Asset Pages
After the integration is set up, your Databricks Workflows jobs will appear in the Sifflet Catalog. Each job has a dedicated asset page that centralizes all relevant metadata, including:
- Metadata from Databricks: Job status, descriptions, and tags.
- Metadata from Sifflet: Custom metadata, ownership information, and documentation added directly in Sifflet.
You can also add these job assets to Data Products to group them logically with other related data assets for better governance and discovery.
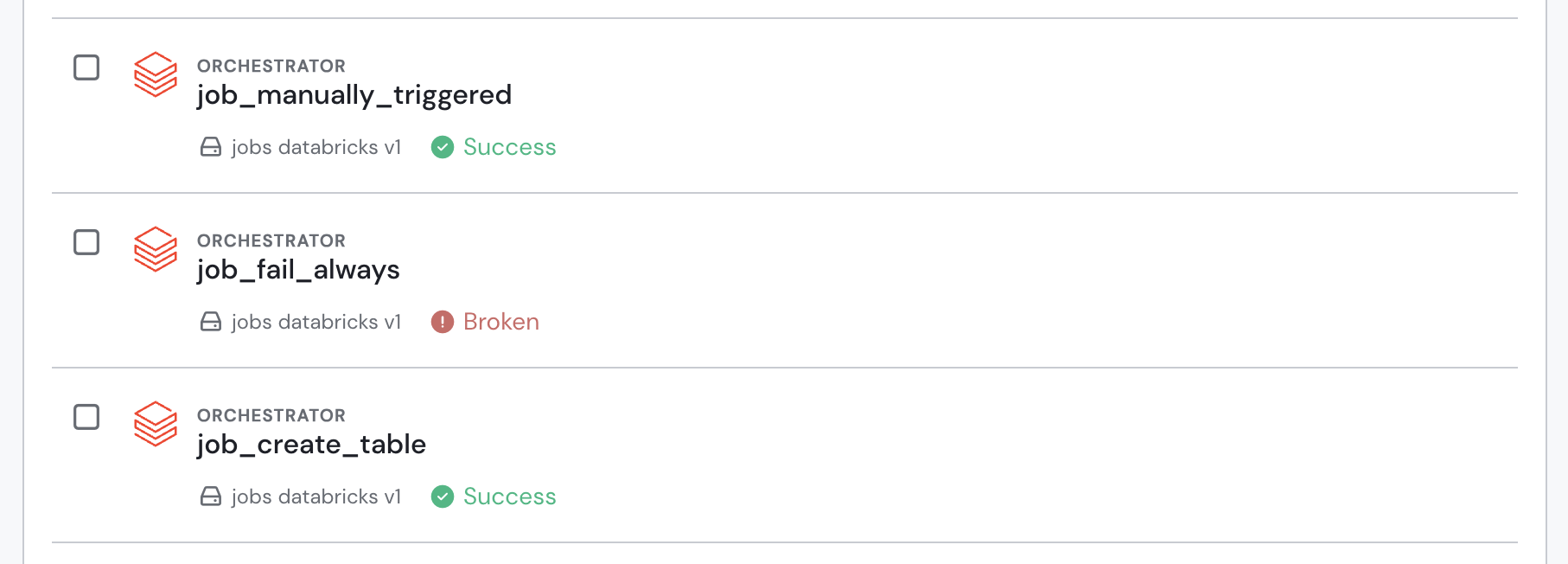
Databricks Workflows jobs in the data catalog
Lineage & Root Cause Analysis
Your Databricks Workflows jobs will be automatically integrated into Sifflet's data lineage graph. This provides a clear, end-to-end view of your data flows, helping you understand which job or workflow generates each data asset and its current status.
This lineage is also leveraged by Sage, Sifflet's root cause analysis AI agent. When an incident occurs, Sage analyzes the lineage to determine if an upstream Databricks job is the potential root cause, speeding up investigation and resolution time.
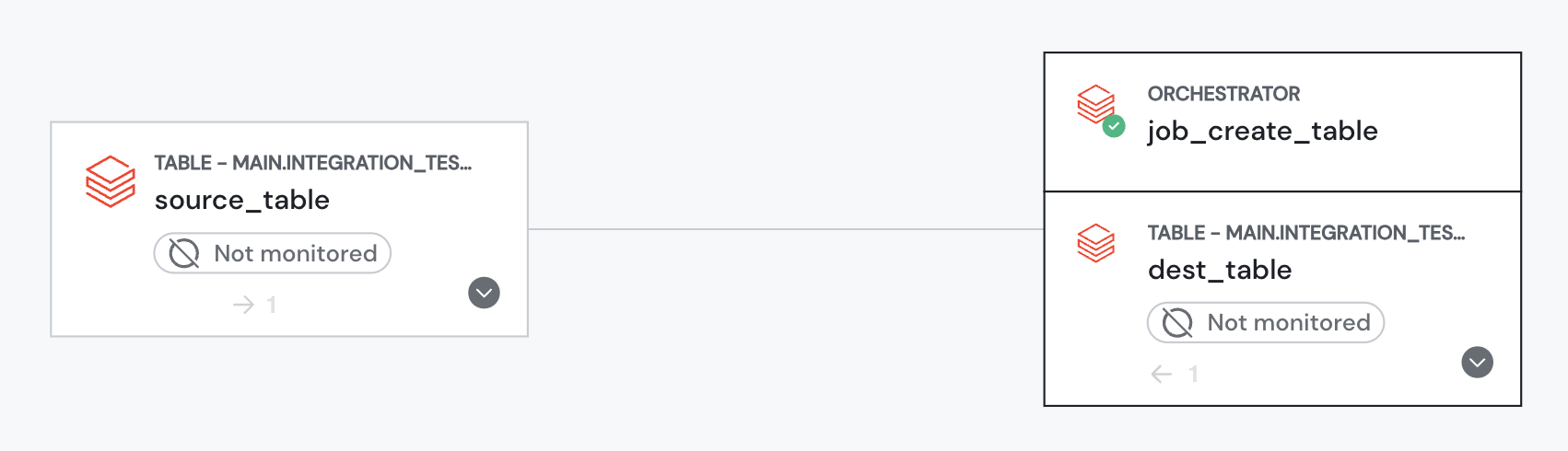
Databricks Workflows jobs in Sifflet lineage
Add Data Quality Gates to your Pipelines
You can add Sifflet monitoring steps directly into your existing Databricks pipelines to act as data quality gates. This allows you to programmatically check the quality of your data during pipeline execution and stop the workflow if a Sifflet monitor fails, preventing bad data from propagating downstream.
Notably, this capability is available through Sifflet's APIs and can be implemented even without adding the formal Databricks Workflows integration in the Sifflet UI.
Updated 8 months ago