Feedback Loop
How to improve the training process of ML models with user-generated input.
Overview
Sifflet ML models offer a way to introduce user-generated input into the training information in a form of a Feedback Loop.
Description
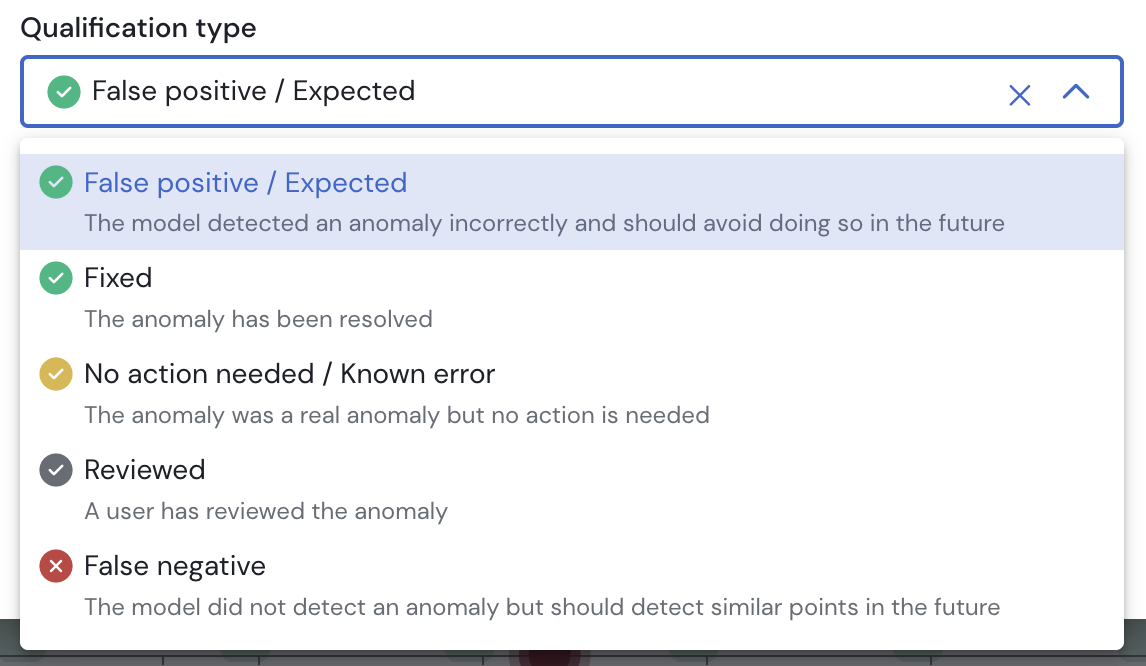
Qualifications
By providing feedback on alerts, it's possible to improve models accuracy. Currently available qualifications are:
- False Positive / Expected - A data point was falsely detected as an anomaly. This can be used to flag points just outside the confidence band or to tell the model that the trend has changed, for example when entering a busy period, and avoid anomalies.
- False Negative - there is an anomaly in data, but the model has not raised it.
- Reviewed - A neutral qualification indicating that the error has been analysed and there is no further action to take.
- Fixed - The anomaly has been fixed. Sifflet can automatically qualify datapoints as fixed if they were previously anomalies and their value has changed and their updated values fall within the expected confidence bounds.
- No Action Needed/ Known Error - This qualification can be used to flag known issues that won't be fixed or don't need to be fixed. The model will ignore this data point.
Data point qualification influence on the modelSome influence
- When qualifying a data point as false positive/Expected, false negative, Sifflet will update the predictions to attempt to detect/not detect similar points as anomalies
- When qualifying a data point as No Action Needed/Known error, the model will ignore it during the prediction process.
No influence
- When qualifying a data point as Reviewed or Fixed, the model will act as normal and not change it's behaviour based on the qualification.
Usage
It's possible to qualify a data point by simply clicking on it. A qualification modal will be displayed.
Examples
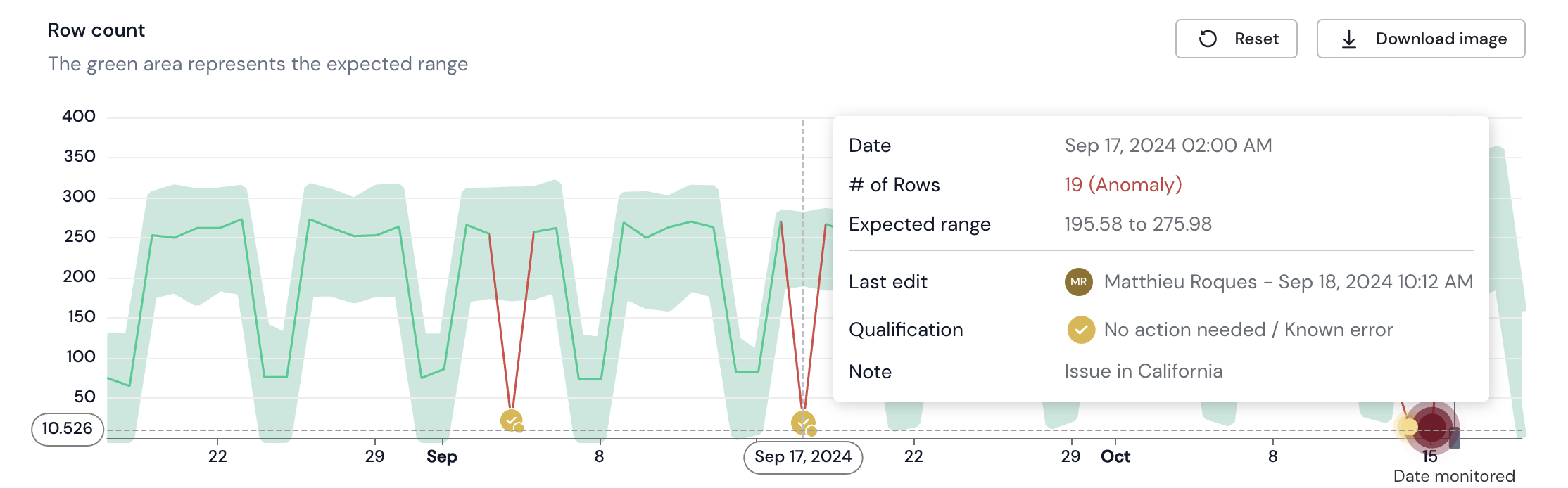
Example 1
In the case below, big drops have been identified in September. After investigation, the root cause has been identified by your team but won't fix it for now. Since it will not be fixed any time soon, and in order to avoid impacting future predictions, you can set the Qualification to "No Action Needed/Known Error".
Example 2
In the case below, an alert has been identified. After investigation, it appears that the alert was inaccurate because the increase and change in trend is an expected business shift.
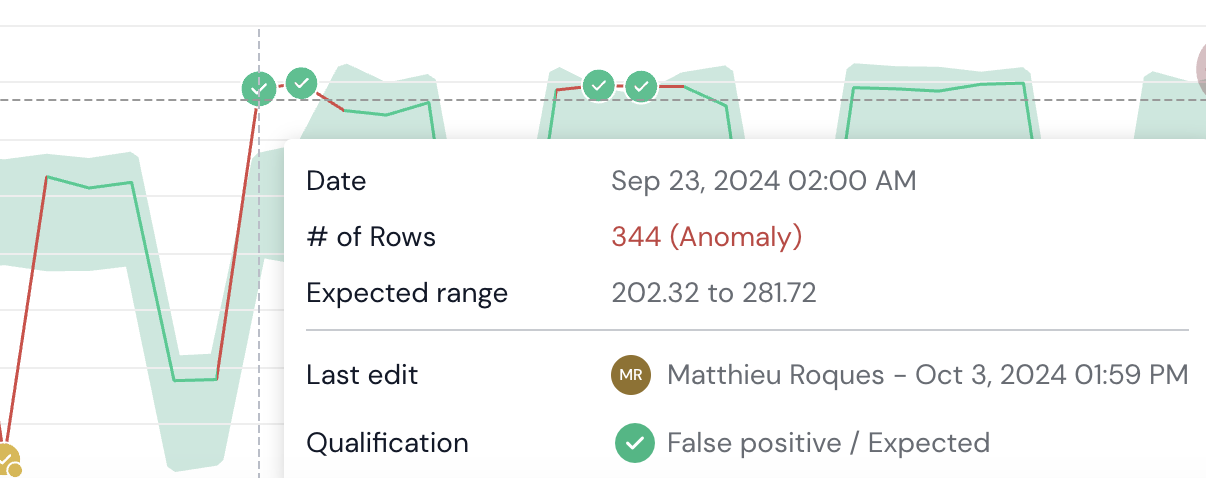
In order to improve future predictions and avoid anomaly noise, a Qualification to "False Positive / Expected" should be applied. As we can see in the example, the model quickly tries to adapt to higher expected values.
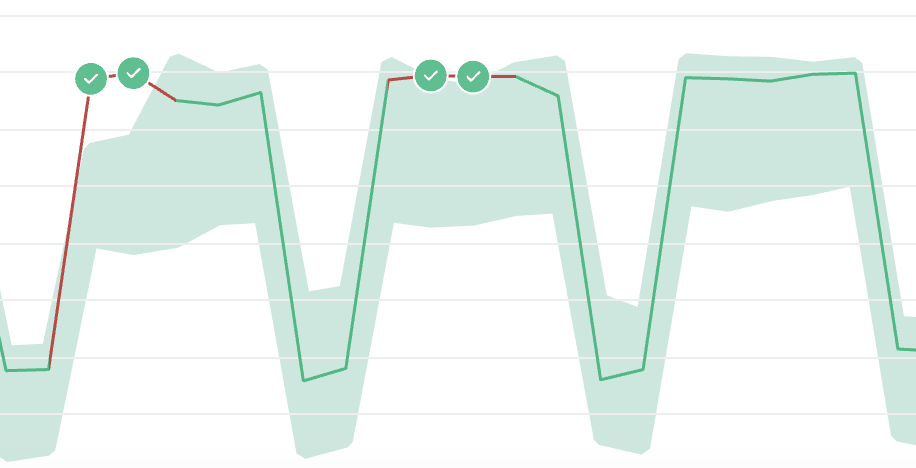
Example 3
Qualify a datapoint as False Negative
If sifflet has failed to detect an anomaly, you can qualify a passing datapoint as False Negative. This will impact the anomaly detection algorithm for future datapoints to avoid considering similar datapoints as passing.
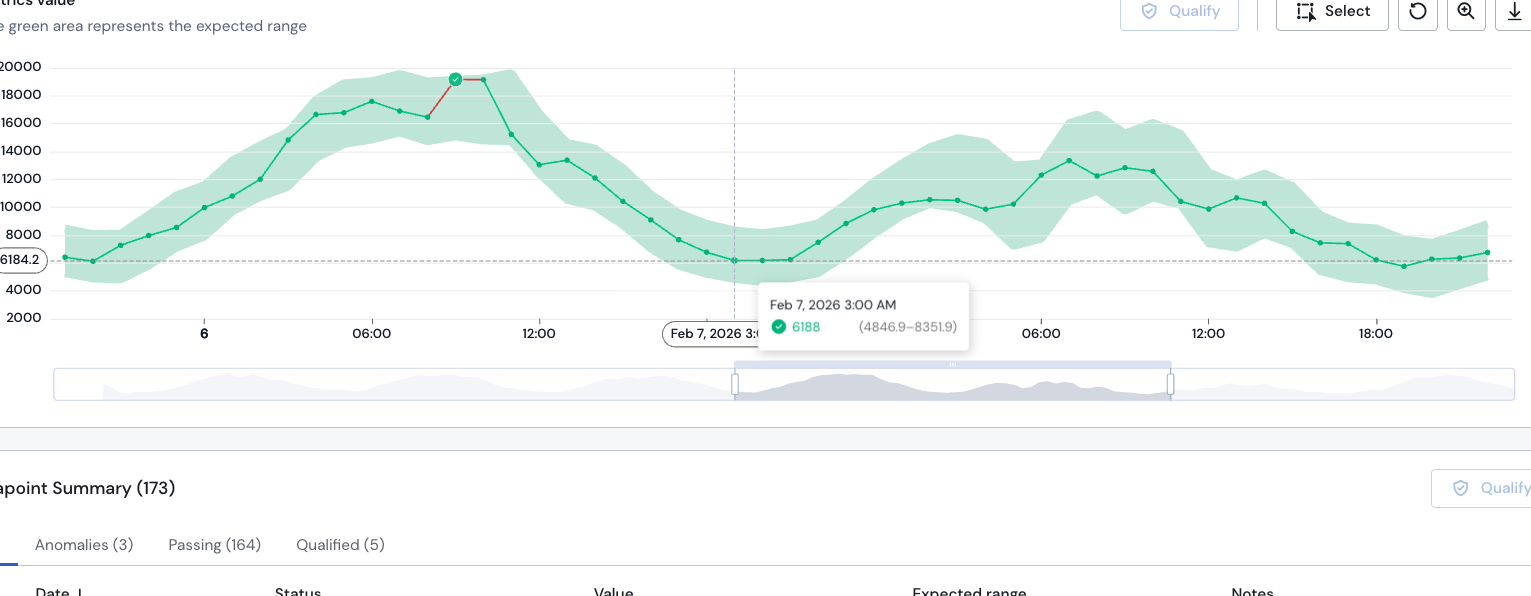
By clicking on any datapoint in the graph you can display the qualification window and select False Negative from the list.
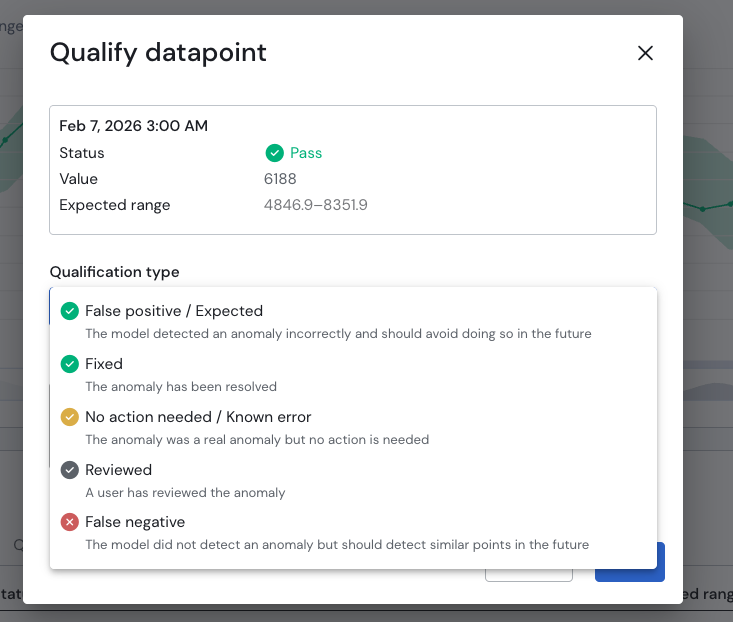
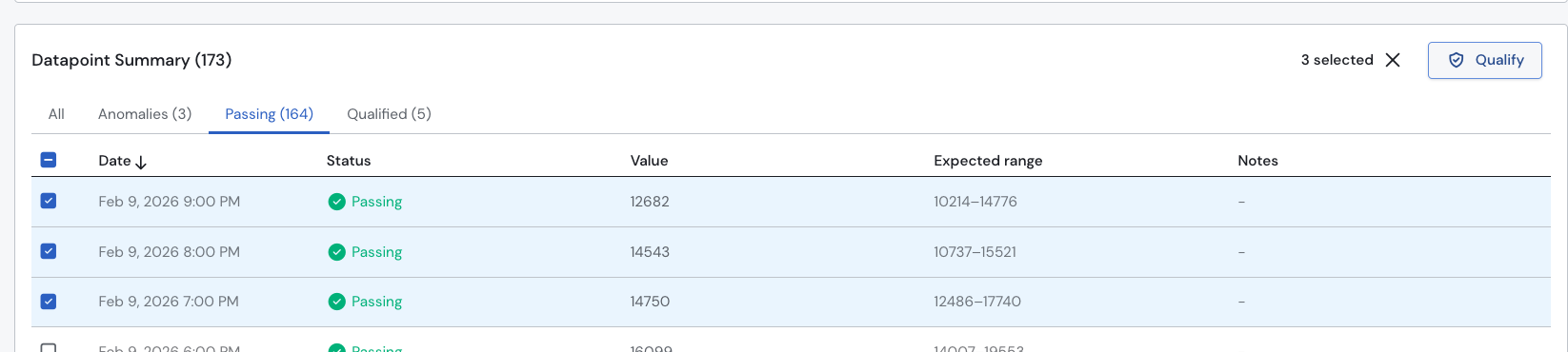
Alternatively, and particularly if you need to do this for several datapoints, you can also navigate to the list of datapoints below the graph and select the datapoint to qualify from the list directly.
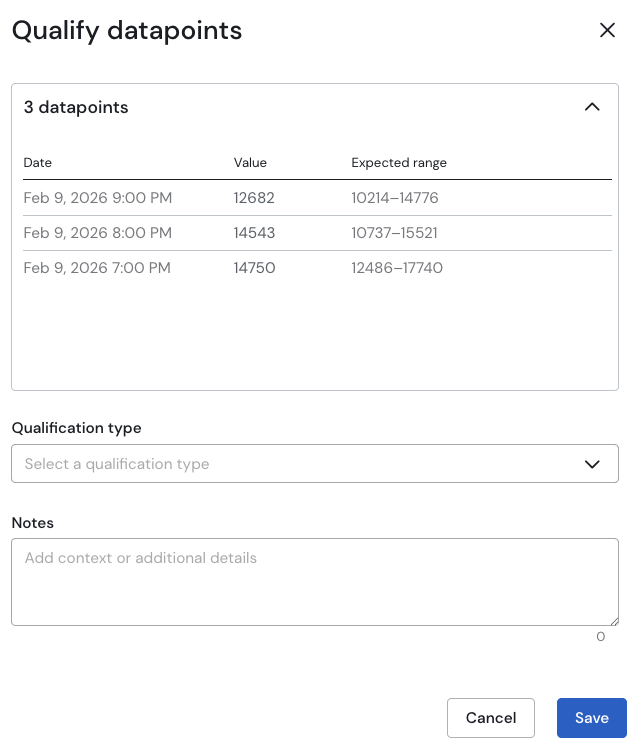
The qualification window shows the list of selected datapoints in this case
Updated 5 months ago