BigQuery
Why connect Sifflet to BigQuery?
By connecting Sifflet to BigQuery, you'll be able to leverage Sifflet's three core capabilities:
- Catalog all your data assets (with valuable metadata retrieved from BigQuery and enriched directly in Sifflet).
- Run monitors on your data assets to detect issues as soon as they arise and allow data consumers to trust the data.
- Benefit from Sifflet's end-to-end lineage that showcases your data pipelines and the assets upstream and downstream of your data platform.
Integration guide
You can integrate Sifflet with BigQuery by following these steps:
- Create a dedicated custom role with the minimal permissions required to interact with BigQuery
- Create a service account and generate a JSON Key file that you will import as a secret in Sifflet
- Create a new source in Sifflet
Check that you have sufficient permissions on GCPYou will need the following GCP roles to configure the different components of the integration:
- Project IAM Admin
- Role Administrator
- Service Account Admin
- Service Account Key Admin
roles/resourcemanager.projectIamAdmin roles/iam.organizationRoleAdmin roles/iam.serviceAccountAdmin roles/iam.serviceAccountKeyAdmin
1. Create a custom role in BigQuery
Create a dedicated custom role in GCP (documentation):
- In your GCP console, under IAM & Admin, go to Roles and create a new role for Sifflet
- Grant the following permissions to the role:
bigquery.datasets.get
bigquery.jobs.create
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
bigquery.jobs.listAll
Field-level lineageThe
bigquery.jobs.listAllpermission is required for our field-level lineage feature to function correctly.
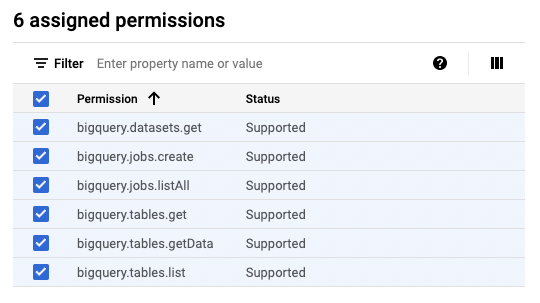
List of permissions that need to be granted to the role
BigQuery lineageSifflet can retrieve the lineage information directly computed by BigQuery. To enable this, you will need to:
- Enable the following APIs in your GCP project: data catalog, BigQuery, and data lineage (documentation)
- Grant the Sifflet service account the following roles (documentation):
roles/datacatalog.viewer,roles/datalineage.viewer, androles/bigquery.dataViewer
OR the below permissions:datalineage.events.get datalineage.events.list datalineage.locations.searchLinks datalineage.processes.get datalineage.processes.list datalineage.runs.get datalineage.runs.list
2. Create a service account
Create a new service account (documentation) and assign it the role created in the previous step:
- Under IAM & Admin, go to Service Accounts and create a dedicated service account
- Select the role you previously created (in the below example, you can find it in Custom section as SiffletRole)
- You can skip the step "Grant users access to this service account"

Creating the service account

Assigning the custom role to the service account
- Once created, select the service account and choose Manage Keys under "Actions":

Accessing the key management page
- You can then create a new key via the following path: Add Key -> Create new key -> JSON format
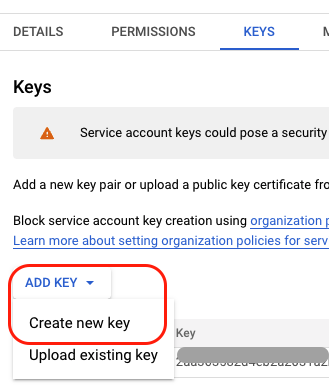
Creating a new key for the service account
- Save the JSON file since you'll need to upload it to Sifflet
3. Create a new source in Sifflet
To connect BigQuery to Sifflet, you will need two items:
- The connection details: your Project ID and Dataset
- The credential: the JSON key file previously saved
Create the credential
To add the JSON key file to Sifflet, please follow the below steps:
- Navigate to the "Credentials" page (you can find it in the side panel by selecting "Integrations" and then "Credentials") and then click on "New credential".
- In the "Credential" area, copy-paste the same content present in the JSON key file.
Create the source
- Navigate to the "Sources" page (you can find it in the side panel by selecting "Integrations" and then "Sources") and then click on the "New source" button.
- Fill out the necessary information collected above. The
Billing Project IDis an optional parameter allowing you to direct Sifflet's query costs to a specific BigQuery project.

The mandatory parameters to create a BigQuery source
- By default, Sifflet refreshes BigQuery metadata once per day. However you can use the frequency parameter to pick a different refresh schedule if required.
FAQ
BigQuery external tables
I have external tables on BigQuery, how does Sifflet handle them?
Sifflet treats your external tables the same way as any regular table on BigQuery: you can find them in the catalog and monitor them.
Sifflet currently supports the following external table types, requiring additional permissions based on the external system:
| External Table type | Supported | Additional rights required |
|---|---|---|
| GCS (Cloud Storage) | ✅ | You can grant the service account the following rights in order to have Viewer access for all GCS buckets/objects: OR You can choose to grant the service account Viewer access only on the buckets referenced by your external tables. |
| Google Drive, Google Sheets | ✅ | You can grant the service account Viewer access only on directories/files referenced by your external tables. |
| GCP BigTable | ❌ |
Unable to add a BigQuery dataset
When creating the source, after pressing "List Datasets" I cannot find the dataset I want to add, is there any configuration issue?
Sifflet will display only the datasets the service account has access to. If you do not see one specific dataset, you might need to review the permissions.
Managing permissions at the dataset granularity
I would like to manage the permissions for the service account at the dataset level, how should I do this?
- Create a role as described in the doc but without the
jobs.createpermission:
bigquery.datasets.get
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
bigquery.jobs.listAll- Create another role with only the following permission:
bigquery.jobs.create- Create a service account as described above and assign it the second role (with the
jobs.createpermission). This will grant the service account the permission at the project level but does not give it access datasets. - For each dataset that you wish to see in Sifflet, follow the below steps:
- In the BigQuery Explorer panel, select a dataset
- Click Sharing -> Permissions
- Click Add Principal
- In the New Principals field: Select or enter the service account you created for Sifflet
- In the "Select a role" List , select the custom role you created in the first step (the one with the 5 permissions)
- Click Save
Billing on another BigQuery project
I would like to bill my queries on another project than the one I am using in production. Is it possible?
In order to better manage the costs associated with the queries executed by Sifflet, you can bill your queries on an additional project, an empty one for instance.
The service account will need the following permissions on the billing project:
bigquery.jobs.createOn the queried project, the permissions needed are:
bigquery.datasets.get
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
bigquery.jobs.listAllYou will just need to specify the Id of the billing project in your data source parameters
Worker Project Ids
What is theWorker Project Ids parameter ?
The Worker Projects Ids is an optional parameter where you can set a list of project ids that you use in BigQuery to query datasets in the Project Id project.
The job history of these worker projects can contain useful usage and lineage information about the datasets in the Project Id project.
If the provided service account has sufficient permissions to query the job history of the worker projects (bigquery.datasets.get to list the datasets and bigquery.jobs.listAll to list the job), then Sifflet will use them to extract additional lineage information on the datasource datasets.
If the service account doesn't have sufficient permissions on these projects, neither the connection test nor the ingestion will fail. The application will simply not use their job history.
Updated 5 months ago