Monitor schema
Use Monitor Version 2Version 1 is now deprecated
Schema
kind: Monitor
version: 2
id: UUID # (friendlyId or id REQUIRED) ID of the monitor
friendlyId: String # (friendlyId or id REQUIRED) friendly string to identify the monitor, unique per dataset
extends: # (optional - default []) List of templates to include in the definition of the monitor. See Templates
- String
name: String # (REQUIRED) Name of the monitor
description: String # (optional - default null) Description for the monitor
tags:
- id: UUID # (optional - default null) ID of the tag
name: String # (optional - default null) Name of the tag
kind: # (optional - default null) Type of tag
"Tag" | "Classification"
terms:
- id: UUID # (optional - default null) ID of the term
name: String # (optional - default null) Name of the term
schedule: String # (optional - default null) Schedule for monitor execution. null for no schedule
# Defined as @hourly/@daily/@weekly/@monthly/@yearly (default to midnight UTC) or CRON expression.
scheduleTimezone: String # (optional - default null) Schedule Time Zone, i.e. Europe/Paris
incident: # (REQUIRED)
severity: # (REQUIRED) Severity of the incident
"Low" | "Moderate" | "High" | "Critical"
message: String # (optional - default null) Custom message to add to the incident and notifications
createOnFailure: Boolean # (optional - default true) Whether or not to create an incident on failure
notifications:
- kind: # (REQUIRED) Kind of notification to send
"Slack" | "Email" | "MicrosoftTeams" | "Jira" | "ServiceNow" | "Webhook"
id: UUID # (optional - default null) ID of the notification
name: String # (optional - default null) Name of the Slack Channel, Email address or Microsoft Teams channel.
templateName: String # (OPTIONAL) For Jira and ServiceNow
datasets: # (REQUIRED) List of datasets to monitor. Most monitors can only have a single dataset
- id: UUID # (optional - default null) ID of the dataset
name: String # (optional - default null) Name of the dataset
datasource:
id: UUID # (optional - default null) ID of the dataset source
name: String # (optional - default null) Name of the dataset
uri: String # (optional - default null) URI of the dataset
parameters: Parameters # (REQUIRED) See Parameters
overrideNotificationRules: Boolean # (optional - default true) Whether or not to create to use custom notifications defined in this form or use notification rules
Referencing a datasetUsers can use the name of the dataset in case there are no conflicts identifying the dataset. Users can rely on the ID of the dataset, the data source name, or the data source ID to prevent any conflict.
Parameters
Identifying Monitors
There are two options to identify a monitor and to ensure any changes to the monitor will not overwrite it and keep all run history.
With id
idkind: Monitor
id: 7edf1177-1a3c-4d71-b85f-e38b773735b4id needs to be a completely unique UUID
With friendlyId
friendlyIdComing up with UUIDs is sometimes not appropriate, friendlyId allows for an alternative. friendlyId Needs to be unique per dataset, this means a dataset cannot have two monitors with the same friendlyId.
kind: Monitor
version: 2
friendlyId: customerEmailUnique
datasets:
- name: sales
datasource:
name: mySqlDatabase
...The above monitor has a friendlyId customerEmailUnique , only one of those monitors can be added to the sales table in our mysqlDatabase.
If the list of
datasetsreferenced in the template is changed with an update, the monitor defined with afriendlyIdwill be deleted and a new one will recreated.To avoid this behavior, you can replace the
friendlyIdwith theidof the monitor (can be found in the UI) and then make your datasets changes.
Referencing other Sifflet objects
The monitor definition references many other Sifflet objects such as: tags, classification tags, terms, datasets, slack channels, teams channels or emails.
To do so, you can use the ID of the object. This will ensure that applying your monitor will link to the correct object.
tags:
- id: 20be41bc-9f0e-4a2f-b7d7-e737051589cd
- id: 6d2d4dfd-8b86-4f7e-871b-7a2fcd29748bHowever, this process of retrieving and using these IDs is very cumbersome. So you can also use more natural identifier like the name of the object.
tags:
- name: Production
- name: Important AssetReferencing by name will work if there is a matching object and if there is no ambiguity (there are not 2 objects with the same name).
In case of ambiguity with the name, you need to use another property to distinguish the different objects.
For instance, for the tags, it can be kind property (if a classification tag and a classical tag are both using the name Production).
tags:
- name: Production
kind: Classification
- name: Important AssetFinally, using the id will always guarantee non-ambiguious reference.
You can also use the id with other properties to provide more context:
tags:
- id: 20be41bc-9f0e-4a2f-b7d7-e737051589cd
name: Production
kind: Classification
- id: 6d2d4dfd-8b86-4f7e-871b-7a2fcd29748b
name: Important AssetIn this case, if the object is renamed or changes kind, the monitor can still be applied. However a Warning will be generated with the mismatch.
For tags
For tags, you can use the id, the name and the kind properties.
For instance:
tags:
- name: To fix
- id: 7edf1177-1a3c-4d71-b85f-e38b773735b4
- id: 20be41bc-9f0e-4a2f-b7d7-e737051589cd
name: Production
kind: Classification
- id: 6d2d4dfd-8b86-4f7e-871b-7a2fcd29748b
name: Important AssetFor terms
For terms, you can use the id and the name properties.
For instance:
terms:
- name: ROI
- id: 7edf1177-1a3c-4d71-b85f-e38b773735b4
- id: 20be41bc-9f0e-4a2f-b7d7-e737051589cd
name: MarketingFor notifications
Email, Slack, Microsoft Teams, Webhook
For Email, Slack, Microsoft Teams and Webhook notifications, you can use the id, the kind and the name properties.
The following parameters are only for custom notifications. If parameter
overrideNotificationRulesfor notifications is set to false , is not taken into consideration.
For instance:
notifications:
- kind: Email
name: [email protected]
- kind: Slack
name: Alerts
id: dd6f06ec-fab1-4a87-9544-b113f496d61d
- kind: Slack
id: 8c2dbfe5-0911-4586-b937-c5f48b7c21d9
- kind: Webhook
name: WebhooknameJira
For Jira notifications, you can use the kind . The template name must match one of the templates configured in the Collaboration Tools settings.
For instance:
notifications:
- kind: Jira
templateName: Template JiraServiceNow
For ServiceNow notifications, you can use the kind .The template name must match one of the templates configured in the Collaboration Tools settings.
For instance:
notifications:
- kind: ServiceNox
templateName: Template ServiceNowFor datasets
For datasets, you can use the id, the name the datasource.id and datasource.name or uri properties.
For instance:
datasets:
- name: Sales
- name: Prices
datasource:
name: BigQuery Data warehouse
- id: 70217023-1a89-4c0b-9b6a-c85192c918b3
- name: company_employees
datasource:
id: ce3e9dd9-b007-42b0-b884-8c419f7f6daa
- uri: snowflake://xyz12345.eu-central-1/DATABASE.SCHEMA.TABLEWith uri
uriURIs helps referencing assets in a unique way without depending on any Sifflet names or IDs. Find out more about URIs
- uri: bigquery:sifflet-demo-project.sandbox_dataset.cbsa_2008_1yr
- uri: snowflake://xyz12345.eu-central-1/DATABASE.SCHEMA.TABLERetrieving IDs from the UI
To get the ID of a dataset, go to the dataset page and click on Copy Data Asset ID button of :
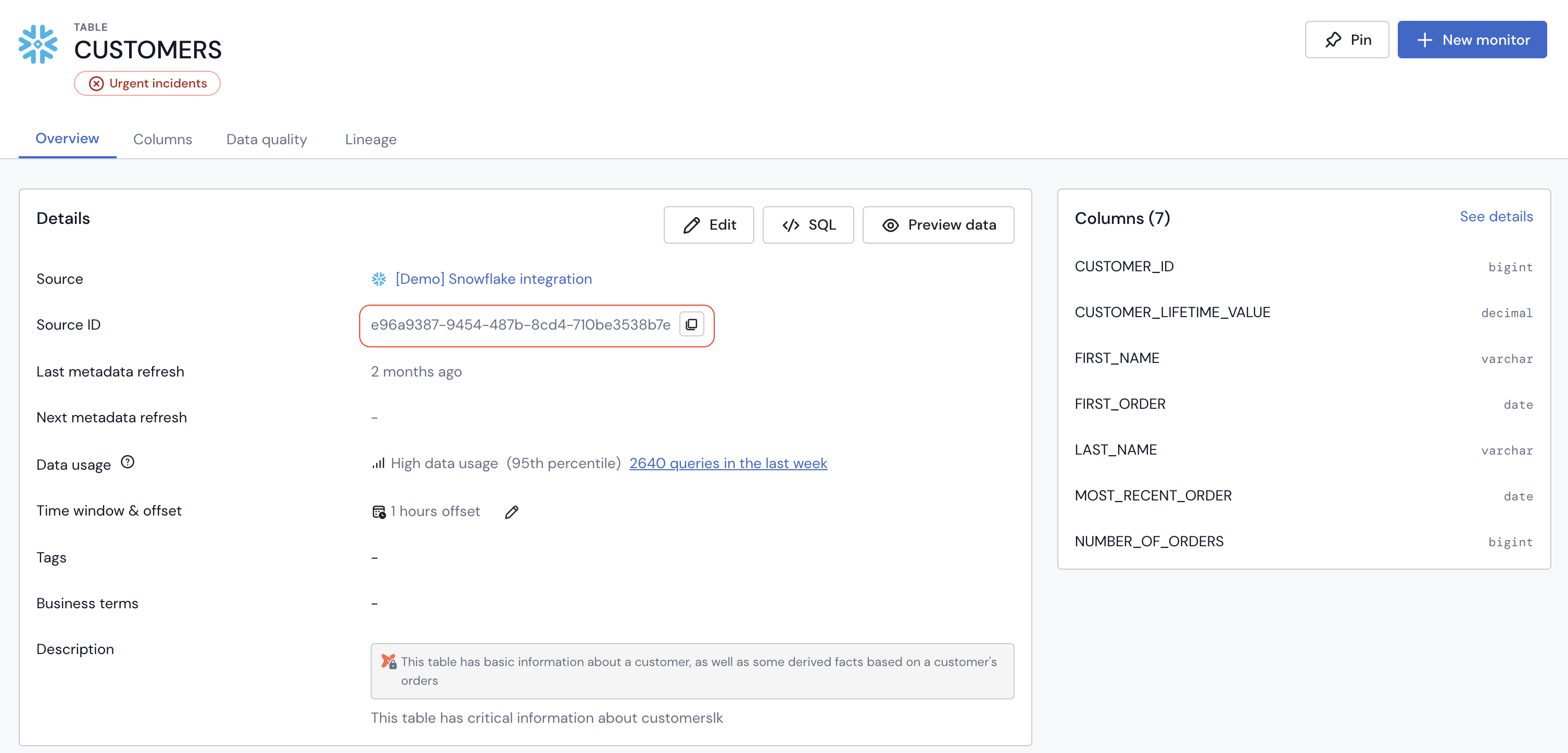
You can get a data source ID from the data source page and when clicking on Copy Source ID
URIsYou can also retrieve URIs from the Catalog's Asset Page.
Examples
Simple example
kind: Monitor
version: 2
id: 998156a0-efc3-429b-b150-38525bc8f0cd
name: Uniqueness on customerEmail
schedule: "@daily"
incident:
severity: Low
datasets:
- name: sales
datasource:
name: mySqlDatabase
parameters:
kind: FieldDuplicates
field: customerEmailComplex example
kind: Monitor
version: 2
id: 998156a0-efc3-429b-b150-38525bc8f0cd
name: Average Monitor on price
description: The monitor fails if the field's average is outside of a given range.
tags:
- name: Low Cardinality
kind: Classification
- name: Production
schedule: 5 4 * * *
incident:
severity: Low
message: Some message
notifications:
- kind: Slack
name: team-data-science
- kind: Email
name: [email protected]
- kind: Email
id: 41df515f-e5b6-4b4e-b684-d9108ac563bf
name: [email protected]
datasets:
- id: 5a93a977-df0b-4f17-b4dd-d12ebe21549d
parameters:
kind: Metrics
field: price
aggregation:
kind: Average
threshold:
kind: Static
min: 1000.0
isMinInclusive: false
groupBy:
field: channel
timeWindow:
field: time
firstRun: P100DMultiple Monitors on the same file
kind: Monitor
version: 2
friendlyId: customerEmailUnique
name: Uniqueness on customerEmail
schedule: "@daily"
incident:
severity: Low
datasets:
- name: sales
datasource:
name: mySqlDatabase
parameters:
kind: FieldDuplicates
field: customerEmail
---
kind: Monitor
version: 2
friendlyId: customerIdUnique
name: Uniqueness on customerEmail
schedule: "@daily"
incident:
severity: Low
datasets:
- name: sales
datasource:
name: mySqlDatabase
parameters:
kind: FieldDuplicates
field: customerIdCommon types
Simple Types
Duration
Applicable to firstRun, frequency,offset,deltaQuerying,rollingTimeWindow
Uses the ISO 8601 format. It only accept a single positive date/time element.
So only the following formats are accepted: PnY (Year unit), PnM (Month unit), PnW (Week unit), PnD (Day unit), PTnH (Hour unit), PTnM (Minute unit), PTnS (Second unit), where n is a positive number or 0.
Examples:
P1Wrepresents 1 weekP2Drepresents 2 daysPT24Hrepresents 24 hoursP0Drepresents 0 days
Note: In most cases, only a subset of units supported (for instance, only Year, Months and Days, but not the other ones). These cases are described in the schema of each monitor.
Date
DateUses the ISO 8601 format: YYYY-MM-DD
Examples:
2023-01-03represents January 3rd, 20232023-12-31represents December 31st, 2023
UUID
UUIDIdentifier using the format: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx where x is an hexadecimal character
Examples:
20be41bc-9f0e-4a2f-b7d7-e737051589cd6d2d4dfd-8b86-4f7e-871b-7a2fcd29748becd00144-153e-479c-b51b-1273271e33ed
Monitor specific types
DynamicThreshold
DynamicThresholdsensitivity: # (optional - default *Normal*) Sensitivity of the ML model
"Low" | "Normal" | "High"
bounds: # (optional - default *LowerAndUpper*) Indicates on which bound to alert
# *Lower* - Alert only if the value is below the expected range
# *Upper* - Alert only if the value is above the expected range
# *LowerAndUpper* - Alert if the value is below or above the expected range
"Lower" | "Upper" | "LowerAndUpper"WhereStatement
WhereStatement(optional - default null) SQL boolean expression used to filter out data from input dataset.
null to disable this filtering.
Examples:
myColumn > 5category LIKE 'production-%'(myColumn > 5 AND myColumn < 25) OR COMPLEX_FUNCTION(category)
GroupBy
GroupBy(optional - default null) Field to use for alerting per category.
null to disable categorical analysis.
Examples:
myColumn
TimeWindow
TimeWindow(optional - default null) Time Window parameters for the query
null to disable using time window
field: String # (REQUIRED) Field to use for time window
firstRun: Duration # (REQUIRED) How many past points to fetch
# Allowed duration units: Days, Hours, Minutes
frequency: Duration # (REQUIRED) Aggregation size
# Can be 1 month, 1 week, 1 day, 1 hour, 30 minutes, 20 minutes, 15 minutes, 10 minutes
# *null* to auto-select aggregation between 1 day and 1 hourOffsets and Lookback
Offsets and LookbackSame as TimeWindow, with the following properties added:
# Same as TimeWindowWithOffset, with the following properties added
offsetPeriods: Integer # (optional - default *null*) Number of time periods based on frequency offset by. 0 will query the current time period. 1 is recommended to query the last complete time period.
# *null* to use the default value of 1 meaning it will query the last complete period
disableDeltaQuerying: Boolean # (optional - default false) Disable the Lookback/delta querying feature
deltaQuerying: Duration # (optional - default 1 day) Lookback/Length of data to re-query at each run
Partition
Partition(optional - default null) If input dataset is partitioned, filter to use on the partitioned column.
kind: # (REQUIRED) Kind of partition to use
"IngestionTime" | "TimeUnitColumn" | "IntegerRange"
# For *IngestionTime* kind, to use
interval: Duration # (REQUIRED)
# For *TimeUnitColumn* kind
field: String # (REQUIRED)
interval: Duration # (REQUIRED)
# For IntegerRange kind
field: String # (REQUIRED)
min: Integer # (REQUIRED)
max: Integer # (REQUIRED)
The partition kind and field must match the partitioning of the input dataset.
kind: Monitor
version: 2
id: 9699f47e-bb01-4514-0001-451424fe4179 # (REQUIRED) ID of the monitor
name: My monitor name # (REQUIRED) Name of the monitor
description: First monitor using CLI # Description of the monitor
tags: # Tags to apply to the monitor
- name: Production
- name: IMPORTANT
terms: # Business Terms to apply to the monitor
- name: ROI
schedule: 31 * * * * # Schedule for the monitor (using CRON format)
incident:
severity: Low # Severity of the incident to create in case of alert
message: "" # Message to add to the incident/alert notification
datasets: # (REQUIRED) Datasets to monitor
- id: 6d8f779d-f6ac-41f7-be74-7237caa76967
parameters: # (REQUIRED) Parameters of the monitor
kind: Metrics # (REQUIRED) Kind of monitor to use
field: price
aggregation:
kind: Average
aggregation:
kind: Sum
threshold:
kind: Static
min: 1000
isMinInclusive: false
Parameters list and example for every monitor typeYou can find the exact list of parameters for every monitor type with examples in this section of the documentation
Threshold
ThresholdSee Threshold
Updated 26 days ago